Activation Function In Neural Network
To put it another way, an artificial neuron calculates the 'weighted total' of its inputs and adds a bias, as illustrated by the net input in the diagram below.
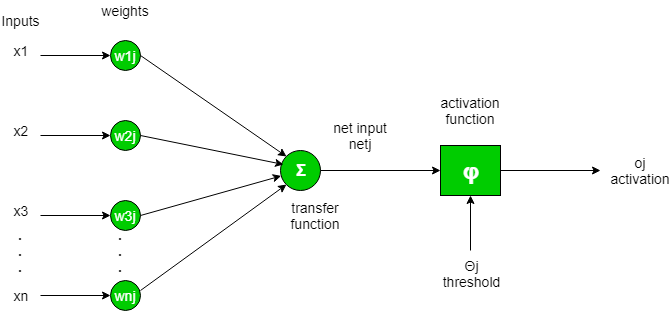
Mathematically

The value of net input can now be anything between -inf and +inf. Because the neuron does not understand how to bind to a value, it is unable to determine the firing pattern. As a result, the activation function is a crucial component of any artificial neural network. They essentially determine whether or not a neuron should be engaged. As a result, the value of the net input is limited.
The activation function is a non-linear change that we apply to the input before passing it to the next layer of neurons or converting it to output.
Types Of Activation Functions
Deep Learning employs several distinct types of activation functions. The following are a few of them:
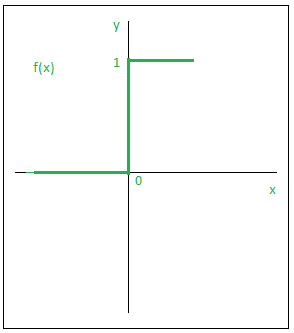
1.Step Function:
One of the most basic types of activation functions is the step function. In this case, we assume a threshold value, and the neuron is triggered if the value of net input, say y, is greater than the threshold.
Mathematically,
textif x>=0, f(x)=1
textif x0 and f(x)=0
Given below is the graphical representation of step function.
2.Sigmoid Function
The sigmoid function is a popular activation method. It is defined as follows:

Graphically.
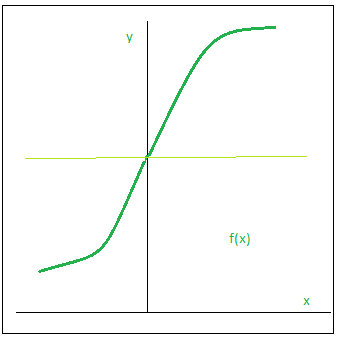
This is a continuous differentiable smooth function. The fact that it is non-linear gives it a significant advantage over step and linear functions. The sigmoid function has an exceptionally amazing characteristic. This simply means that if I have numerous neurons with sigmoid activation function in neural network, the output will also be non linear. The function has a S form and ranges from 0 to 1.
3.ReLU
The Rectified linear unit (ReLU) is a function. It's the most used activation method. It is defined as follows:

Graphically,
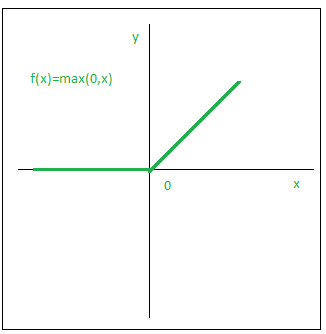
The key benefit of employing the ReLU function over other activation functions is that it does not simultaneously stimulate all of the neurons. What exactly does this imply? If you look at the ReLU function if the input is negative it will convert it to zero and the neuron does not get activated.
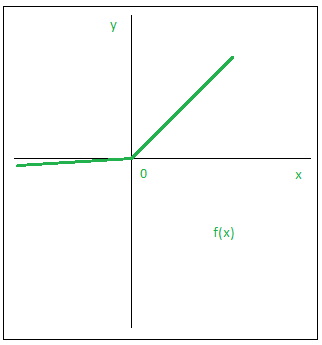
4.Leaky ReLU
The Leaky ReLU function is a better variant of the ReLU function. We define the Relu function as a small linear component of x, rather than specifying it as 0 for x less than 0. It can be summed up as follows:
Graphically,
InsideAIML is the platform where you can learn AI based content by the help of certain types of courses.
.jpg)

Comments
Post a Comment